

In late August, a keen-eyed Scottish redditor noticed something unusual: the Scots language version of Wikipedia seems to not actually be written in the Scots language. This, of course, is a serious problem. As the redditor points out,
The Scots language version of Wikipedia is legendarily bad. People embroiled in linguistic debates about Scots often use it as evidence that Scots isn’t a language, and if it was an accurate representation, they’d probably be right. It uses almost no Scots vocabulary, what little it does use is usually incorrect, and the grammar always conforms to standard English, not Scots.
For those unaware, Scots is a language from the Scottish lowlands – it diverged from English in the twelfth century and has been variously described as an indigenous language, a dialect, or a regional variant of English.
This puts it in a similar class to other minority languages, such as Irish Gaelic or Kashubian. These regional languages often have a strong cultural history, but are threatened with extinction. The Scots language is estimated to be spoken by around 1.5 million people.
How an American teenager became a Scots expert
As it turns out, almost the entirety of the Scots Wikipedia was written by one extremely prolific American teenager. It should be noted that they don’t even speak Scots – they simply use common Scots spellings for certain words and graft them onto pure English grammar.
Needless to say, this isn’t exactly a great look for an already-contested language. What’s worse is the extent of their work – since 2013, this single editor wrote more than 200,000 (!) articles on the Scots Wikipedia, easily becoming the most active user of the community.
In this light, comments such as this are very much warranted:
It turns out an American teen who identifies as an “INTP brony” has singlehandedly written almost the entirety of Scots wikipedia despite not knowing the language at all. Scottish redditors suspect he may have done “more damage to the Scots language than anyone else in history.” https://t.co/FuaXMQjHkr
— dream song 4 (@chickenpaprika) August 25, 2020
Why is this important?
This discovery is important on many levels. For starters, it highlights how vulnerable regional dialects and minority languages are. A single American teenager has inadvertently delegitimized Scots as a language in the eyes of many. Incidents such as these can lead to the diminishing importance of the language among the general public.
For us, this is interesting on another level. Accessibility is one of the most important aspects of chatbot development – for us, the best case scenario would be to support every single language on the planet.
Chatbots can play a major role in protecting endangered languages. This goes beyond just supporting the existing population – they can also be used as educational aides! A major factor in protecting regional languages is providing a sort-of “support ecosystem”. That is to say, the more services supporting a given language, the more likely it is to grow and thrive.
Unfortunately, with minority languages, we face a certain issue: the lack of large volumes of text that can be used as training data. In order to train a chatbot to support Scots, a large amount of work by specialised linguists is required.
There is, however, a shortcut – using public data that’s already out there. Wikipedia is one such resource, but it only works if we can trust the data.
In a situation where the majority of a given language’s Wikipedia is edited by a single person who doesn’t even speak the language… Well, you can see the problem.
This was highlighted by NLP researcher Robyn Speer on Twitter:
Almost every article on Scots Wikipedia is written by one American teenager, who does not speak Scots and is just writing English in an “accent”.
If you have a multilingual language model, this fakery might be your _entire training data_ for Scotshttps://t.co/Rc1wkA0S2P
— Robyn Speer (@r_speer) August 25, 2020
What does this mean for chatbots?
This entire debacle only proves that tempting as they are, public datasets must be used with extreme caution. After all, AI solutions are only as good as their training models – if you feed them with junk data, don’t expect anything other than junk performance.
Here at SentiOne, we cooperate with leading European learning institutions to make use of their linguistic expertise in order to train our chatbots on verified, high-quality data. Although we aren’t supporting Scots yet, we’re working hard to support as many languages as we can.
As for the Scots Wikipedia? There’s always a silver lining to every story – the scandal caused a spike in mentions for the phrase “Scots language”, as well as a corresponding rise in Google searches for the term.
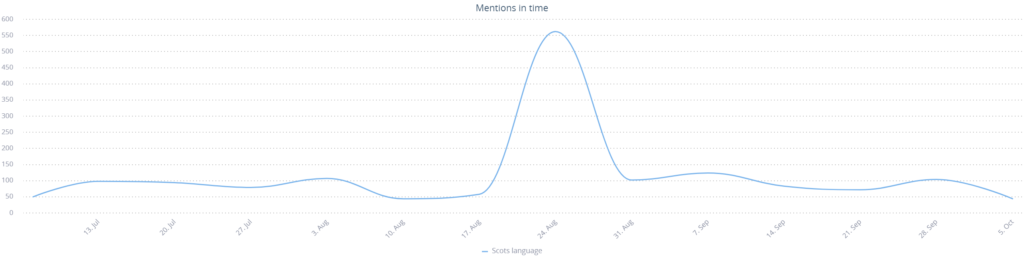
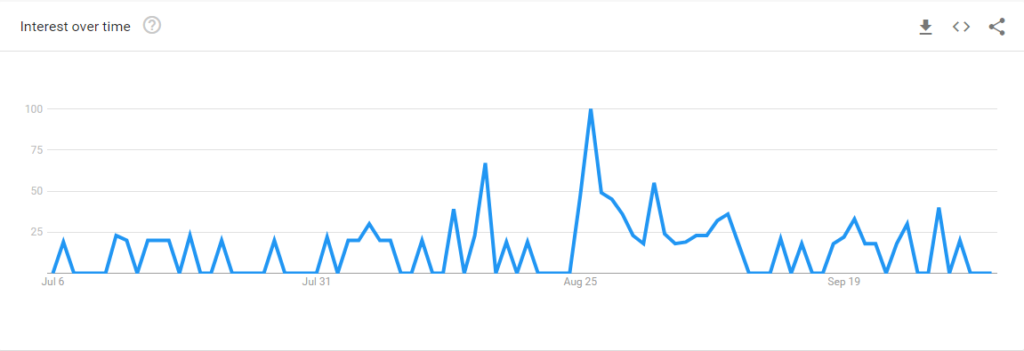
This is good news – blips like these are often indicative of rising interest in a topic. The Wikipedia project has started a cleanup project for the Scots Wikipedia, with linguists such as Michael Dempster of the Scots Language Centre in a prominent role.
Other minority language Wikipedia projects have also started internal audit processes to ensure they’re trustworthy and reliable. For now, though, the standing orders remain as they have always been – double-check your data!
If you were planning to use the Scots Wikipedia as your training dataset, be aware – r/ScottishPeopleTwitter might actually be a better training source, if you can excuse the sarcasm.






