

Pod koniec sierpnia bieżącego roku, pewien spostrzegawczy użytkownik portalu Reddit odkrył coś nietypowego: Wikipedia w języku Scots wcale nie jest napisana językiem Scots. To, oczywiście, jest duży problem – wręcz niespodziewany. W słowach redditora:
Wikipedia w języku Scots jest fatalna. Osoby zaangażowane w debaty lingwistyczne używają jej często jako dowodu na to, że Scots nie jest językiem – i gdyby faktycznie reprezentowała Scots, mieliby rację. Jednak nie używa ona praktycznie żadnego słownictwa Scots (a jeśli już, to robi to błędnie), a gramatyka zawsze odpowiada standardowemu językowi angielskiemu.
Język Scots – nie mylić z językiem szkockim – pochodzi z nizinnej części Szkocji. Posługuje się nim około półtora miliona ludzi. Odłączył się od staroangielskiego w dwunastym wieku, przez co jest różnie nazywany językiem rdzennym lub regionalnym wariantem angielskiego.
Stawia go to w podobnej sytuacji co język kaszubski lub gwara śląska. Języki te mają silne powiązania kulturalne z regionem, ale grozi im wyginięcie.
Jak nastolatek z Ameryki stał się Szkotem
Okazało się, że niemalże całość wikipedii Scots została napisana przez pojedynczego nastolatka ze Stanów Zjednoczonych. Warto dodać, że ów nastolatek nie mówi w języku Scots – używa po prostu pisowni charakterystycznej dla tego języka w tekstach pisanych czystym językiem angielskim.
Łatwo więc zobaczyć, jaki problem może to sprawiać językowi który i tak jest już zagrożony. Skala problemu jest porażająca – od 2013 roku, ta pojedyncza osoba napisała ponad 200,000 (!) artykułów, z łatwością stając się najbardziej aktywnym członkiem społeczności.
Komentarze takie jak ten są więc jak najbardziej na miejscu:
It turns out an American teen who identifies as an „INTP brony” has singlehandedly written almost the entirety of Scots wikipedia despite not knowing the language at all. Scottish redditors suspect he may have done „more damage to the Scots language than anyone else in history.” https://t.co/FuaXMQjHkr
— dream song 4 (@chickenpaprika) August 25, 2020
Wychodzi na to, że amerykański nastolatek określający się jako “INTP Brony” własnoręcznie napisał prawie całość Wikipedii Scots pomimo kompletnej nieznajomości języka. Szkoccy Redditorzy podejrzewają, że mógł on “wyrządzić więcej szkód językowi Scots niż ktokolwiek w historii”.
Dlaczego jest to ważne?
Sprawa jest poważna – na wielu płaszczyznach. Po pierwsze, podkreśla jak bardzo zagrożone są języki regionalne. Pojedynczy nastolatek zdelegitmatyzował Scots jako język w oczach wielu. Tego typu incydenty prowadzą bezpośrednio do coraz szybszej utraty statusu języka w danej społeczności.
Dla nas sprawa jest intrygująca z innego powodu. Dostępność jest jednym z najważniejszych aspektów budowania chatbotów. Nie mówimy tu o dostępności technicznej, czyli pracy 24/7/365. Chodzi o dostępność dla danych osób – na przykład dla mniejszości etnicznych posługujących się językami innymi niż “mainstreamowe”.
Chatboty nie są tylko doskonałym narzędziem obsługi klienta – mogą one również odgrywać istotną rolę w ochronie języków zagrożonych, właśnie poprzez oferowanie obsługi mniejszościom etnicznym oraz jako pomoc edukacyjna. Języki zagrożone chroni się poprzez zapewnianie “ekosystemu” wsparcia – im więcej narzędzi i usług wspiera dany język, tym łatwiej jest go popularyzować.
W przypadku języków mniejszościowych, niestety, mamy do czynienia z konkretnym problemem: brak dużych ilości tekstu reprezentujących dany język. Jeśli chcielibyśmy wesprzeć język typu Scots, musielibyśmy poświęcić mnóstwo zasobów na pracę z wyspecjalizowanym zespołem lingwistów.
Niektórzy wolą jednak iść na skróty i korzystać z danych publicznych. Wikipedia jest definitywnie jednym z najlepszych zasobów tego typu; problem pojawia się, kiedy nie możemy ufać tego typu danym. W sytuacji, gdzie okazuje się, że dana wersja językowa jest pisana w całości przez kogoś, kto nie potrafi posługiwać się danym językiem… Widzicie sami, gdzie leży problem.
Badaczka NLP Robyn Speer zwróciła na to uwagę na Twitterze:
I believe that the cld2, cld3, and fastText language detectors all have Scots (sco) as one of the languages they claim to detect, and all of them are getting their belief about what Scots is from Wikipedia
— Robyn Speer (@r_speer) August 25, 2020
Wierzę, że algorytmy cld2, cld3 i fastText “wspierają” Scots jako jeden ze swoich języków. Wszystkie z nich korzystają z Wikipedii jako swojego zbioru danych.
Co oznacza to dla chatbotów?
Cała ta sprawa udowadnia, że publiczne zbiory danych należy wykorzystywać z ogromną dozą ostrożności. AI jest tak dobre, jak jej dane treningowe: jeśli trenujemy nasz algorytm na śmieciowych danych, nie powinna nas dziwić śmieciowa jakość pracy.
W SentiOne współpracujemy z wieloma instytucjami naukowymi w całej Europie: dzięki ich doświadczeniu lingwistycznym jesteśmy w stanie trenować nasze chatboty wykorzystując zweryfikowane zbiory danych o wysokiej jakości. O ile nie wspieramy – jeszcze – języka Scots, nasza metodologia pozwala nam na stałe rozszerzanie naszego wachlarza języków.
Jeśli chodzi o samą Wikipedię, wszystko ma swoje dobre strony – skandal ten doprowadził do wzrostu zainteresowania językiem Scots, co widać na wykresach ilości wzmianek i wyszukań Google na ten temat.
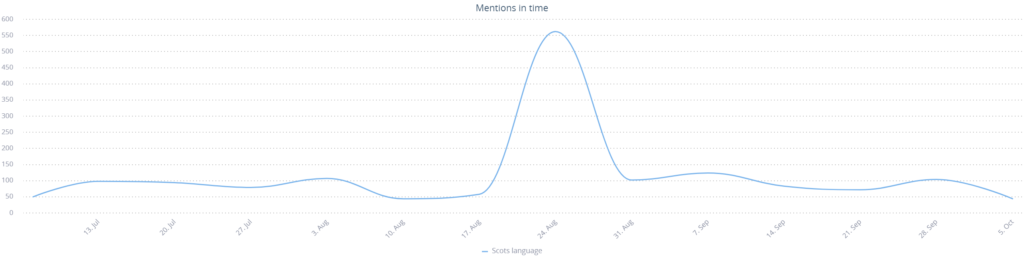
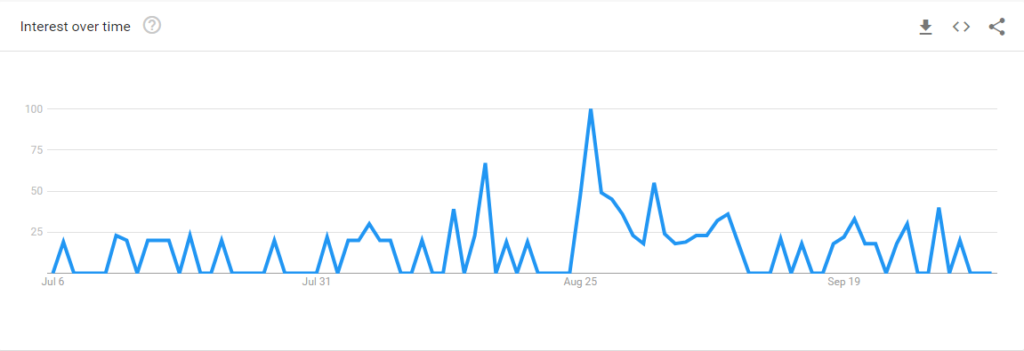
Wikipedia rozpoczęła też współpracę z lingwistami takimi jak Michael Dempster ze Scots Language Centre aby “posprzątać” wersję Scots.
Inne warianty językowe Wikipedii również rozpoczęły wewnętrzne audyty, aby upewnić się że przedstawiają języki mniejszościowe w dokładny sposób. Dla nas cała historia jest po prostu wartościową lekcją: ZAWSZE sprawdzajmy nasze dane!
Jeśli myślisz o wykorzystaniu Wikipedii Scots jako swojego zbioru danych badawczych, miej na uwadze że nawet r/ScottishPeopleTwitter jest lepszym źródłem, jeśli nie przeszkadza Ci wyjątkowo skoncentrowany sarkazm.





