

Table of contents
- NLU and NLP – Understanding the Process
- Crucial NLU Components
- How to Train Your NLU
- Best Practices for NLU Training
- Start with a preliminary analysis
- Ensure that intents represent broad actions and entities represent specific use cases
- Avoid using similar intents
- Don’t overcomplicate phrases
- When possible, use predefined entities
- Make sure your intents and entities are semantically distinct
- Standardise your naming structure
- Have enough quality test data
- Continuously review your phrases once the bot is live
- Watch out for overfitting
- SentiOne Automate – The Easiest Way to Training NLU
- Article Summary
Throughout the Bot Building Series, we’ve been pretty adamant about the importance of training your chatbot as a key to its success and by extension, the success of your brand. Now it’s time to hammer this point home. We’ll get into the weeds of training the NLU model, show you some best practices, and hopefully get you set on the road to success!
NLU and NLP – Understanding the Process
First, let’s tackle the topic of NLU vs NLP – what is the difference, if any? These two acronyms both look similar and stand for similar concepts, but we do need to learn to distinguish them before proceeding.
Natural Language Processing (NLP) is a general theory dealing with the processing, categorisation, and parsing of natural language. Within NLP functions the subclass of NLU, which focuses more so on semantics and the ability to derive meaning from language. This involves understanding the relationships between words, concepts and sentences. NLU technologies aim to comprehend the meaning and context behind the text rather than just analysing its symbols and structure.
Essentially, NLU is dedicated to achieving a higher level of language comprehension via sentiment analysis or summarisation, as comprehension is necessary for these more advanced actions to be possible.
Crucial NLU Components
To properly understand what makes NLUs tick, we need to establish some basic definitions that we’ll be coming back to throughout the rest of the article:
- Intents: generally speaking, customers will interact with your bot because they want help with something, which is what we refer to as intent. These can vary from looking up information to booking a service or procedure, but your starting point when perfecting your NLU should be to establish what intents your NLU is already familiar with, which ones you should add, and which ones have been underperforming.
- Phrases (or utterances): these are the actual inputs your users send to communicate with your chatbot or voice bot. As we mentioned in our article on multilingual chatbots, implementing ChatGPT to quickly generate large amounts of phrases your customers may use is worth considering when you want to expedite work.
- Entities: these are parts of phrases that carry a significant amount of semantic relevance. This is where Natural Language Understanding really flexes its muscles, as interpreting entities and associating them with actual values programmed into the NLU is what puts it a cut above the capabilities of NLP. Entities allow us to understand key details from a phrase or sentence, which then allows the technology to categorise them e.g., such as name or location.
- Variables: they are strictly related to entities in that whatever meaning-bearing entity (like a name or date) is introduced by your user, your chatbot can save as a variable for future use to increase personalisation (e.g., entity: name, variable: Andrew, or entity: location, variable: London).
How to Train Your NLU
With the basic groundwork laid down, we can now proceed to the real stuff and answer the big question: how do you actually train your Natural Language Understanding model?
Training an NLU requires compiling a training dataset of language examples to teach your conversational AI how to understand your users. Such a dataset should consist of phrases, entities and variables that represent the language the model needs to understand.
This process involves a little bit of fine-tuning. Initially, the dataset you come up with to train the NLU model most likely won’t be enough. As you gather more intel on what works and what doesn’t, by continuing to update and expand the dataset, you’ll identify gaps in the model’s performance. Then, as you monitor your chatbot’s performance and keep evaluating and updating the model, you gradually increase its language comprehension, making your chatbot more effective over time.
To start, you should define the intents you want the model to understand. These represent the user’s goal or what they want to accomplish by interacting with your AI chatbot, for example, “order,” “pay,” or “return.” Then, provide phrases that represent those intents. If you’re running a pizza shop, the intent “order,” for example, needs phrases like “I want to get a cheese pizza,” “I’d like to order a cheese pizza” and so on since there are many ways a customer may express their desire to order a pizza.
From the list of phrases, you also define entities, such as a “pizza_type” entity that captures the different types of pizza clients can order. Instead of listing all possible pizza types, simply define the entity and provide sample values. This approach allows the NLU model to understand and process user inputs accurately without you having to manually list every possible pizza type one after another.
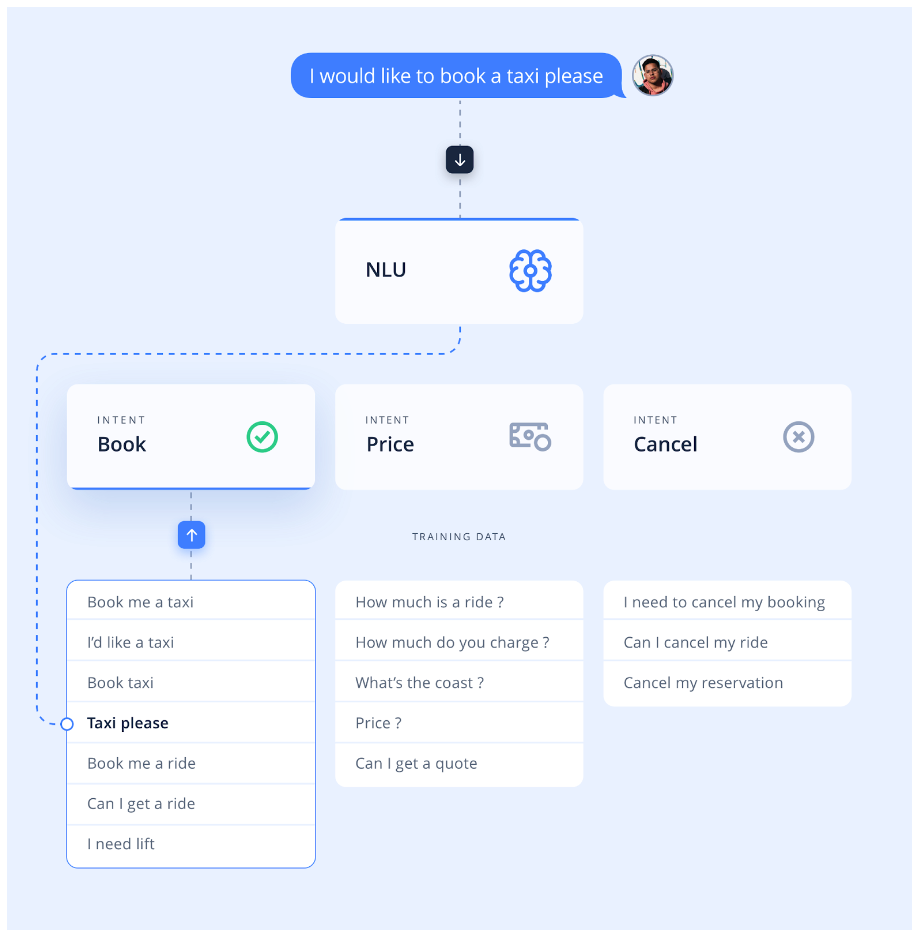
How does an NLU model work
Best Practices for NLU Training
1. Start with a preliminary analysis
The first good piece of advice to share does not involve any chatbot design interface. All you will need is a whiteboard or just a pen and paper. You see, before adding any intents, entities, or variables to your bot-building platform, it’s generally wise to list the actions your customers may want the bot to perform for them. Brainstorming like this lets you cover all necessary bases, while also laying the foundation for later optimisation. Just don’t narrow the scope of these actions too much, otherwise you risk overfitting (more on that later).
2. Ensure that intents represent broad actions and entities represent specific use cases
A layered approach is always the best. Your intents should function as a series of funnels, one for each action, but the entities downstream should be like fine mesh sieves, focusing on specific pieces of information. Creating your chatbot this way anticipates that the use cases for your services will change and lets you react to updates with more agility. No matter how great and comprehensive your initial design, it’s common for a good chunk of intents to eventually completely obsolesce, especially if they were too particular.
Generally, it’s recommended to create 15–20 phrases for each intent. You’ll notice this isn’t an astronomical number, and that’s deliberate – when intents change, the phrases associated with them need to change as well, and that’s potentially a whole boatload of avoidable work. Entities are much more relaxed because of their granularity, making it easier to change them without causing a cascade of “oh God why is nothing working anymore”-class events, so create as many as you need.
Here’s a quick example comparing a safe and “not safe” way to build an intent infrastructure:
| Not Safe | Safe |
|---|---|
| activate card, activate account | activate (+ entities: card, account) |
| remind login, recover password | recover (+ entities: login password) |
| loan | view, change (+ entities: loan, details) (+ entities: loan, repayment) |
| payment | view, help (+ entities: payments, methods) (+ entities: payment, failure) |
3. Avoid using similar intents
Over time, you’ll encounter situations where you will want to split a single intent into two or more similar ones. “Pay_credit” and “pay_debit” is a classic example. Yet, in your noble attempt to be forward-thinking and intelligently anticipate problems before they pop up, you may unintentionally create more difficulty for the model to properly recognise and differentiate these nuanced intents. When this happens, most of the time it’s better to merge such intents into one and allow for more specificity through the use of extra entities instead.
4. Don’t overcomplicate phrases
We get it, not all customers are perfectly eloquent speakers who get their point across clearly and concisely every time. But if you try to account for that and design your phrases to be overly long or contain too much prosody, your NLU may have trouble assigning the right intent.
Just because a client once said, “I’m calling because I have a credit card, and, well I was hoping it provides some kind of insurance but I didn’t find anything about it, would it be possible for you to check that for me?” does not mean all of that has to go and gunk up your NLU. “Can you check if my credit card provides some insurance?” – that’s a much better training phrase. Leading with a simple opening and using content-bearing keywords and verbs, like “credit card,” “provide insurance,” “open,” “foreign currency account,” and “online” is the key to an efficient NLU that’s able to accurately extract the meaning even when the input is a raving preamble. Keeping your phrases direct and simple is the way to go 99% of the time.
5. When possible, use predefined entities
Using predefined entities is a tried and tested method of saving time and minimising the risk of you making a mistake when creating complex entities. For example, a predefined entity like “sys.Country” will automatically include all existing countries – no point sitting down and writing them all out yourself. Work smarter, not harder.
Speaking of, if you want to get your NLU in working order ASAP, SentiOne Automate offers reliable, built-in entities that are very easy to incorporate. No manual work required!
6. Make sure your intents and entities are semantically distinct
Beginners can quickly get tangled in the two concepts, and if you don’t create these two items with appropriate levels of semantic distinction, your NLU will simply not work properly.
As an example, suppose someone is asking for the weather in London with a simple prompt like “What’s the weather today,” or any other way (in the standard ballpark of 15–20 phrases). To not confuse the Natural Language Understanding of your chatbot, the intent (user’s goal) should be labelled as “getweather” or “getforecast,” and your entities ( the information that fulfils the intent) should be “time” (e.g. today), “location” (e.g. London), “weather_condition” (e.g. raining) etc. Your entity should not be simply “weather”, since that would not make it semantically different from your intent (“getweather”).
7. Standardise your naming structure
Messy code is just not maintainable. This applies to your NLU infrastructure as well. A clean, consistent naming scheme for your entities and intents ensures there won’t be any confusion, especially when multiple developers or bot designers are working on the project. As a general rule, use underscores and/or capitalise the first part of each word, and avoid spaces or dashes in the names. See the example below:
| Default context | FAQ | Small talk | Processes |
|---|---|---|---|
| booking_new | |||
| booking_change | |||
| bot_greetings | faq_insurance | smalltalk_age | booking_cancel |
| bot_bye | faq_loan | smalltalk_creator | card_new |
| bot_functions | faq_petpolicy | smalltalk_joke | card_activate |
| faq_payment | smalltalk_insult | card_block | |
| appointment_new | |||
| appointment_cancel |
8. Have enough quality test data
Employing a good mix of qualitative and quantitative testing goes a long way. A balanced methodology implies that your data sets must cover a wide range of conversations to be statistically meaningful. 15–20 phrases per intent is once again the target to shoot for. As for entities, it’s entirely up to you.
For quality, studying user transcripts and conversation mining will broaden your understanding of what phrases your customers use in real life and what answers they seek from your chatbot.
9. Continuously review your phrases once the bot is live
Checking up on the bot after it goes live for the first time is probably the most significant review you can do. It lets you quickly gauge if the expressions you programmed resemble those used by your customers and make rapid adjustments to enhance intent recognition. And, as we established, continuously iterating on your chatbot isn’t simply good practice, it’s a necessity to keep up with customer needs.
10. Watch out for overfitting
Overfitting occurs when the model cannot generalise and fits too closely to the training dataset instead. When setting out to improve your NLU, it’s easy to get tunnel vision on that one specific problem that seems to score low on intent recognition. Keep the bigger picture in mind, and remember that chasing your Moby Dick shouldn’t come at the cost of sacrificing the effectiveness of the whole ship.
To prevent overfitting, implement diverse training data (phrases, sentence structures, terminology and even synonyms based on the way people would ask the question) to make the bot understand your users, without tailoring the entirety of your model to one particular mannerism or use case.
SentiOne Automate – The Easiest Way to Training NLU
Hopefully, this article has helped you and provided you with some useful pointers. If your head is spinning and you feel like you need a guardian angel to guide you through the whole process of fine-tuning your intent model, our team is more than ready to assist. Our advanced Natural Language Understanding engine was pre-trained on over 30 billion online conversations, achieving a 94% intent recognition accuracy. But what’s more, our bots can be trained using additional industry-specific phrases and historical conversations with your customers to tweak the chatbot to your business needs. Get in touch with our team and find out how our experts can help you.
Article Summary
Learn how to successfully train your Natural Language Understanding (NLU) model with these 10 easy steps. The article emphasises the importance of training your chatbot for its success and explores the difference between NLU and Natural Language Processing (NLP). It covers crucial NLU components such as intents, phrases, entities, and variables, outlining their roles in language comprehension. The training process involves compiling a dataset of language examples, fine-tuning, and expanding the dataset over time to improve the model’s performance. Best practices include starting with a preliminary analysis, ensuring intents and entities are distinct, using predefined entities, and avoiding overcomplicated phrases.




