#FacebookDown – what happened?
Poniedziałek nie był szczęśliwym dniem dla Facebooka. Zarówno on, jak i Instagram i Whatsapp (które należą do Facebooka) zniknęły pod wieczór z sieci, pozostając niedostępnymi do późnej nocy.
Nie trzeba tłumaczyć, że szybko stało się to Dużym Problemem. #AwariaFacebooka szybko stała się najbardziej trendującym hashtagiem nocy.
Co stało się z Facebookiem?
Kiedy zaczęły pojawiać się pierwsze doniesienia o awarii, sieciowcy z całego świata zaczęli szukać przyczyn awarii. Pierwszym podejrzanym był system DNS.
5 minut przed awarią Facebooka ktoś nacisnął enter…
…i po chwili zaklnął pod nosem siarczyście. pic.twitter.com/wVFTFARVRS— Niebezpiecznik (@niebezpiecznik) October 4, 2021
DNS jest klejem łączącym cały internet – to dzięki niemu możecie po prostu wpisać w przeglądarkę “sentione.com” zamiast zapamiętywania naszego adresu IP (213.186.34.10). Awaria DNS oznacza, że adresy “czytelne” przestają mieć znaczenie – w wyniku czego nie można połączyć się z danym serwisem.
Problem okazał się leżeć nieco głębiej niż DNS. Przyczyną była konfiguracja BGP. Jeśli DNS jest papierową mapą internetu, to BGP jest nawigacją znajdującą najszybszą drogę z punktu A do punktu B.
"We [Facebook] also describe our in-house BGP software implementation, and its testing and deployment pipelines. These allow us to treat BGP like any other software component, enabling fast incremental updates." https://t.co/j3E58nOglG
— Chris Wysopal (@WeldPond) October 4, 2021
Jak każda inna firma o takiej skali, Facebook polega na swojej własnej implementacji BGP. Według inżynierów Facebooka, ich podejście do BGP traktuje protokół jak każdą inną część oprogramowania backendu, co pozwala na “szybkie stopniowe zmiany”. Właśnie taka szybka zmiana doprowadziła do awarii – plik konfiguracyjny z błędem został wpuszczony na produkcję.
W kilka chwil Facebook zniknął z sieci.
Live replay of Facebook disappearing off the internet.#facebookdownhttps://t.co/4SeWPvBWNF pic.twitter.com/U5gbgcPtRd
— Kim Karlsson (@ParanoidVoxel) October 4, 2021
Problem sięgnął też Instagrama i Whatsappa – dwóch aplikacji należących do Facebooka. Ich awaria była jednak nieco zadziwiająca, ponieważ oparte są one o serwery Amazon Web Services zamiast tych należących do Facebooka.
Rozprzestrzenienie awarii na te serwisy doprowadziło do powstania hashtagu #InternetShutdown.
Po bardziej szczegółowe wyjaśnienie awarii zapraszamy do lektury wyczerpującego opisu sytuacji na blogu CloudFlare (po angielsku).
W jaki sposób #AwariaFacebooka wpłynęła na internet?
Awaria jednego serwisu może wydawać nam się dosyć błahą sytuacją – w końcu działa tyle innych miejsc w sieci, na których możemy trochę się pośmiać z sieciowców Facebooka!
Łatwo jednak zapomnieć, że dla dużej części świata Facebook jest całym internetem. W krajach rozwijających się inwestycje i infrastruktura Facebooka umożliwiają dziesiątkom milionów osób tani dostęp do internetu. Awaria najbardziej dotknęła właśnie nich – mieszkańcy tych krajów znaleźli się nagle odcięci od internetu.
Jest to doskonały przykład największego błędu nowoczesnego internetu. Poleganie na kilku gigantycznych korporacjach stoi w sprzecznością z jedną z podstawowych założeń sieci – ma ona być zdecentralizowana. W ten sposób zachowałaby sprawność nawet w przypadku wojny nuklearnej – wszystko dzięki unikaniu tzw. “pojedynczych punktów awarii”.
Poleganie na Facebooku jako jedynemu dostawcy infrastruktury sieciowej wprowadza właśnie taki punkt. To analogiczna sytuacja do tej z czerwca, gdy awaria w Fastly położyła dziesiątki różnych serwisów.
1990: The Internet is a magical distributed system that instantly routes around any instability, surviving lines being cut, servers crashing, and even nuclear war.
2021: Three companies own the internet and one of them broke.
— Daniel Feldman (@d_feldman) October 4, 2021
Nieco bliżej domu, Mark Zuckerberg odczuł skutki awarii natychmiast: jego majątek zmalał o siedem miliardów dolarów w kilka godzin. Nawet szeregowi pracownicy Facebooka poczuli ból: awaria dotknęła też serwis operujący zamkami elektronicznymi na kampusie firmy, zamykając ludzi w biurach i salach konferencyjnych.
Facebook employees can’t enter the headquarters because their badges don’t work, and those already inside can’t enter various rooms because access is linked through the IoT (Internet of Things) and so goes through the same DNS routes that no longer exist:#FacebookDown pic.twitter.com/8hAea9ZG4l
— Leah McElrath 🏳️🌈 (@leahmcelrath) October 4, 2021
Czy awaria Facebooka dotknęła SentiOne?
Na szczęście – nie. O ile Facebook jest jednym z naszych głównych źródeł danych, na szczęście nie jest jedynym.
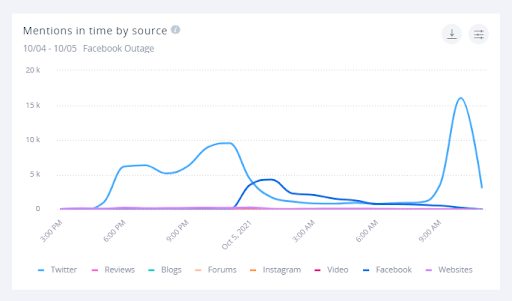
SentiOne dalej prowadziło zbieranie danych social listeningu z innych serwisów i stron internetowych. Kiedy Facebook wrócił do świata żywych zaczęliśmy z powrotem otrzymywać dane również i z tej platformy, bez żadnych problemów. Możemy nawet zobaczyć dokładny moment rozwiązania awarii na naszym wykresie poniżej:
Jak media społecznościowe zareagowały na awarię Facebooka?
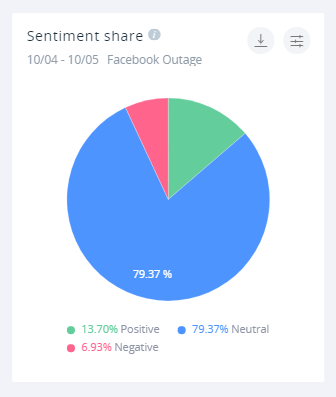
Okazało się, że użytkownicy mediów społecznościowych przyjęli awarię z humorem i zdrową dozą schadenfreude kosztem sieciowców Facebooka.
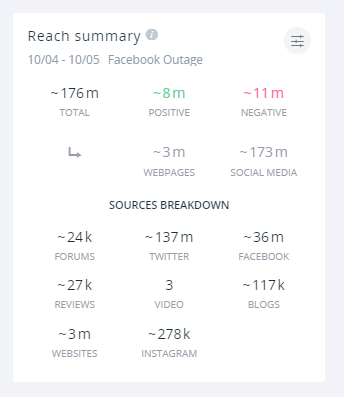
Twitter był, jak zawsze, punktem największej dyskusji – ponad 137 milionów wyświetleń!